
前端架构的演进
如果你是一个经历过几个前端时代的开发者,那你大概能体会:技术的发展从来都不是一蹴而就的,它往往是在一堆痛点里逼出来的。最近开始整理自己在实习期间的收获并参与了一些面试,突然发现其实这几个词说起来都挺常见,但真要搞清楚它们的前因后果、适用场景、技术演化路径,很多人脑子里还是一团浆糊。
所以我想写点东西,从背景聊起,一步一步地梳理一下前端架构的演变过程。不是什么科普型的概念文,更像是一次架构心路复盘,可能偏实战和个人经验,但也希望你能从中找到点共鸣。
从传统到现代:MPA 的起点
最早做 Web 的时候,页面结构简单,服务端是核心,一切逻辑基本都靠后端搞定。你访问一个页面,服务器返回完整 HTML,点个链接就是发请求,整个页面刷新。每个页面都像一个独立的小岛,逻辑自成一体。这就是传统的多页面应用,也就是我们常说的 MPA。
那会儿前端基本是刀耕火种,最复杂的交互也就是 jQuery 写点动画,表单校验。MPA 的好处在于简单直接,部署方便、SEO 友好。但它的问题也很明显,尤其是在用户体验和前后端协作方面,比如页面间状态共享几乎不可能,动不动就白屏刷新,页面跳转卡顿感强,交互复杂点就得各种 hack。
但在那个时代,业务规模也没今天这么复杂,MPA 已经能满足绝大多数需求,算是一个非常实用的解决方案。
SPA 的爆发:前端的高光时刻
真正让前端地位发生质变的是 SPA。React、Vue 横空出世,整个开发范式被彻底颠覆。SPA 的本质是整个网站只有一个 HTML 页面,所有页面切换都靠前端路由完成,组件按需渲染,数据通过 API 异步加载。
这种模式带来了前所未有的用户体验:点击切换没有刷新,数据交互即点即得,组件复用变得高效且自然。更重要的是,前后端彻底分离,前端不再只是写模板的角色,而是站上了业务逻辑实现的第一线。但随之而来的痛点也不少,比如首屏加载慢、首包巨大、SEO 不友好,还要自己搞一堆性能优化、拆包、懒加载,服务端渲染(SSR)甚至成了 SPA 的标配。当然,势必也会存在多人开发相关的问题。
所以说,SPA 带来的是能力和自由,但也意味着更多的责任和复杂度。
SPA vs MPA
为了更直观地比较 SPA 与 MPA 的差异,我们来看一张对比表:
| 对比维度 | SPA 单仓(单页应用,统一仓库) | MPA 多仓(多页应用,多个仓库) |
|---|---|---|
| 📦 代码管理 | ✅ 统一仓库便于共享基础库和统一管理 ❌ commit/分支混乱,权限难控 | ✅ 项目维度划分清晰,权限易控 ✅ 提高协作效率 |
| 🧱 项目构建效率 | ❌ 构建时间长(甚至半小时以上) ❌ 所有模块构建打包一起 | ✅ 每个仓库单独构建,速度快 |
| 🚀 技术体系 | ❌ 强制统一框架、工具链等,限制创新 | ✅ 各仓库可独立技术栈演进(如 Vue 和 React 共存) |
| 🔄 用户体验 | ✅ SPA 无需整页刷新,跳转流畅 ✅ 资源复用,性能更好 | ❌ 每次页面跳转都刷新页面,割裂感强 ❌ 资源重复加载 |
| ♻️ 模块复用 | ✅ 共享组件库,统一运营组件、OpenAPI | ❌ 公共部分每个系统重复造轮子 |
| ⚙️ 功能灰度与发布 | ❌ 无法多功能并行灰度,发布互相阻塞 ❌ 回滚相互影响 | ✅ 各自灰度、发布互不干扰 ✅ 可单独回滚 |
| 🧩 系统通信 | ✅ 单体内系统间通信方便 | ❌ 跨系统通信复杂或做不到 |
| 🔧 运维管理 | ✅ 可统一运维、权限管理 | ❌ 难以统一运维通知或权限策略 |
| 📈 性能表现 | ✅ 局部更新、预加载提升性能 | ❌ 页面整页刷新,加载慢 |
| 🔍 错误监控粒度 | ❌ 错误难以精确定位模块 | ✅ 每个仓库独立监控,粒度更细 |
| ✅ 场景适用 | 适合对用户体验要求极高的大一体化平台,如「企业管理平台」「中台产品」 | 适合独立业务线产品并行研发,如「商城系统」「多个后台项目并存」 |
⛽️ SPA 路由渲染的思路
前端路由通过监听路由的变化,进而对路由进行劫持,渲染路由对应的视图。
例如,对于 Hash 路由,在路由发生变化时会触发 hashchange 事件,所以我们可以监听 hashchange 事件,并在事件发生时加载对应的路由就可以实现页面的切换。
再比如,对于 History 路由,通过 history.pushState 和 history.replaceState 这两个 api ,浏览器可以实现无刷新跳转,利用这个特性也可以实现前端路由。
此外,用户可以通过点击浏览器左上角的后退或者前进,来实现回到上一个页面或者前进一个页面,也可以通过 history.go、history.forward 和 history.back 来实现同样的效果。上述的这些行为,都会触发 popstate 事件,所以不管是使用 Hash 模式还是 History 模式,我们都可以通过监听 popstate 事件来处理用户的返回、前进操作。
当项目变大:微前端的登场
当项目越做越大、团队越来越多,一个 SPA 项目动辄几十个页面、上百个组件,协作成本高得吓人。前端之间的“协作焦虑”开始涌现:技术栈迭代滞后、构建时间冗长导致的编译部署效率低下、团队协作困难、功能模块相互污染、渐进式重构难以实施等。
这时候微前端成了救命稻草。它的核心理念是:把一个前端应用拆成多个“子应用”,每个子应用独立开发、独立构建、甚至可以独立部署,主应用只负责“组装”和“调度”。前端虽然被分解成一些更小、更简单的能够独立开发、测试、部署的应用或模块,而在用户看来仍然是内聚的单个产品。
我们做中台的时候,体验最深。几个部门同时做一个平台,每个模块独立成子应用,各自用熟悉的框架、各自上线回滚,互不干扰,团队配合效率翻了几倍。
当然它也带来新问题,比如子应用之间的状态通信、样式隔离、路由统一等等,都是架构设计上要慎重考虑的。但如果你的项目确实大到那个程度,微前端绝对是个值得探索的方向。
字节微前端解决方案:Garfish
🔍 基本使用
import Garfish from 'garfish';
Garfish.run({
// 子应用的基础路径
basename: '/',
// 子应用挂载点,
domGetter: '#subApp',
apps: [
{
// 子应用名称,也是子应用唯一标识,不可重名
name: 'react',
// 子应用激活路径,当路由变化时 Garfish Router 将根据此信息匹配加载的子应用
activeWhen: '/react',
// 子应用入口地址,
entry: 'http://localhost:3000' // html入口
},
{
name: 'vue',
activeWhen: '/vue',
entry: 'http://localhost:8080/index.js' // js入口
}
]
});import ReactDOM from 'react-dom';
import App from './App';
export const provider = () => {
return {
// 和子应用独立运行时一样将子应用渲染至对应的容器节点
// 根据不同的框架使用不同的渲染方式
render({ dom, basename, props }) {
ReactDOM.render(
<App basename={basename} {...props} />,
dom ? dom.querySelector('#root') : document.querySelector('#root')
);
},
destroy({ dom, basename }) {
// 使用框架提供的销毁函数销毁整个应用
// 销毁框架中可能存在的副作用,并触发应用中的一些组件销毁函数
// 需要注意的时一定要保证对应框架得销毁函数使用正确
// 否则可能导致子应用未正常卸载影响其他子应用
ReactDOM.unmountComponentAtNode(
dom ? dom.querySelector('#root') : document.querySelector('#root')
);
}
};
};
// 这能够让子应用独立运行起来,以保证后续子应用能脱离主应用独立运行,方便调试、开发
if (!window.__GARFISH__) {
ReactDOM.render(<App basename="/" />, document.querySelector('#root'));
}总结一下,Garfish 实现了三个方面的运行时能力:
- 命中路由并加载子应用,这一部分由 Router 来实现;
- 渲染子应用,这一部分由 Loader 来实现;
- 沙箱隔离,这一部分由支持多实例的 Sandbox 来实现;
Router
和前文提到的 SPA 路由思路相似,Garfish 里的 Router 实现思路也是劫持路由,对关键的 API 及事件进行劫持与监听,在路由发生变化的时候展示对应的子应用即可。而加载哪一个子应用,会根据我们在前面基座文件里配置的 activeWhen 字段来判断。
此外,activeWhen 还可以避免子应用的路由冲突:Garfish 会根据此参数自动计算出子应用的 basename 并透传给子应用,子应用设置这个 basename 作为自身路由系统的 basename,保证了全局唯一的情况下就避免了路由冲突。
Garfish Router 在保证应用独立运行的前提下能够做到不破坏如同 SPA 的用户路由体验。
🔍 展开代码
/**
* @garfish/router/src/agentRouter.ts
*/
export const normalAgent = () => {
// 添加监听器:监听 Garfish 定义的自定义路由事件
// __GARFISH_BEFORE_ROUTER_EVENT__
// 当监听到事件时,触发 RouterConfig.routerChange
// 以及 linkTo 逻辑(通常用于路由跳转处理)
const addRouterListener = function () {
window.addEventListener(__GARFISH_BEFORE_ROUTER_EVENT__, function (env) {
RouterConfig.routerChange && RouterConfig.routerChange(location.pathname);
linkTo((env as any).detail);
});
};
// 如果还未标记“已经注入监听器”
if (!window[__GARFISH_ROUTER_FLAG__]) {
// 重写 history.pushState 和 history.replaceState 方法
// 目的:在调用这些 API 发生历史记录变更时,派发自定义事件通知 Garfish 主框架
const rewrite = function (type: keyof History) {
const hapi = history[type]; // 原始方法
return function (this: History) {
const urlBefore = window.location.pathname + window.location.hash;
const stateBefore = history?.state;
const res = hapi.apply(this, arguments); // 执行原方法
const urlAfter = window.location.pathname + window.location.hash;
const stateAfter = history?.state;
// 如果路由或状态发生变化,则派发自定义事件
if (
urlBefore !== urlAfter ||
JSON.stringify(stateBefore) !== JSON.stringify(stateAfter)
) {
window.dispatchEvent(
new CustomEvent(__GARFISH_BEFORE_ROUTER_EVENT__, {
detail: {
toRouterInfo: {
fullPath: urlAfter,
query: parseQuery(location.search),
path: getPath(RouterConfig.basename!, urlAfter),
state: stateAfter
},
fromRouterInfo: {
fullPath: urlBefore,
query: parseQuery(location.search),
path: getPath(RouterConfig.basename!, urlBefore),
state: stateBefore
},
eventType: type
}
})
);
}
return res;
};
};
// 替换原始 API
history.pushState = rewrite('pushState');
history.replaceState = rewrite('replaceState');
// 监听 popstate(浏览器前进/后退按钮)
window.addEventListener(
'popstate',
function (event) {
// 如果事件是 garfish 特殊触发的,就跳过处理
if (event && typeof event === 'object' && (event as any).garfish)
return;
// 清理某个用于标记“是否更新”的状态字段
if (history.state && typeof history.state === 'object')
delete history.state[__GARFISH_ROUTER_UPDATE_FLAG__];
// 派发自定义事件通知 Garfish 主应用
window.dispatchEvent(
new CustomEvent(__GARFISH_BEFORE_ROUTER_EVENT__, {
detail: {
toRouterInfo: {
fullPath: location.pathname,
query: parseQuery(location.search),
path: getPath(RouterConfig.basename!)
},
fromRouterInfo: {
fullPath: RouterConfig.current!.fullPath,
path: getPath(
RouterConfig.basename!,
RouterConfig.current!.path
),
query: RouterConfig.current!.query
},
eventType: 'popstate'
}
})
);
},
false
);
// 设置标志,防止重复注册
window[__GARFISH_ROUTER_FLAG__] = true;
}
// 最后注册自定义路由监听器
addRouterListener();
};Loader
Loader 是 Garfish 的加载器,在整个框架中负责子应用的加载过程,包括对资源的(预)加载、解析、缓存等能力。
Garfish 对子应用的加载分为两个阶段:子应用资源准备阶段 和 app 渲染阶段。
第一个阶段:Loader 要做的工作有子应用资源的下载和解析、parse HTML 之后构造 AST 并抽象出 HTML/CSS/JS 三类资源节点、过滤 ESM、资源处理、缓存资源、创建 App 实例等精细的工作。整个流程比较复杂但是之后对资源的可控性大大提升。
第二个阶段:环境初始化、编译、创建容器、渲染 DOM 树、处理各类资源、路径转换、生命周期的维护,最终目的是获取到 App 实例的 provider 并调用其 render 完成渲染。
🔍 如何获取到 provider
- 子应用必须打包成
umd规范:
module.exports = {
output: {
libraryTarget: 'umd'
}
};// 传入的第二个参数函数就会被挂载在 self 上
(function webpackUniversalModuleDefinition(root, factory) {
if (typeof exports === 'object' && typeof module === 'object')
module.exports = factory(); // CJS
else if (typeof define === 'function' && define.amd) define([], factory); // AMD
// 浏览器
else {
var a = factory();
for (var i in a) (typeof exports === 'object' ? exports : root)[i] = a[i];
}
})(self, () => {
return /******/ (() => {
// webpackBootstrap
var __webpack_exports__ = {};
/*!***********************!*\
!*** ./src/index.tsx ***!
\***********************/
function sayHello() {
console.log('hhh');
}
/******/ return __webpack_exports__;
/******/
})();
});- Garfish 使用的是
CJS规范,因此我们在运行时可以模仿CJS伪造出环境变量,按照正确的格式提供exports和module就可以将导出挂载到module.exports之上,之后再通过exports.module.provider获取并控制子应用的挂载和卸载等生命周期。
// 创建一个空的导出对象(类似 Node.js 里的模块导出机制)
const exports = {};
const module = { exports }; // CommonJS 模块定义:module.exports 是实际导出对象
// 模拟调用一个使用 UMD 格式写的模块代码
(function(module, exports) {
// 假设这段是你打包后的 umd_code,例如:
exports.hello = function () {
console.log('Hello World');
};
})(module, exports);
// 现在你可以使用模块返回的功能
console.log(module.exports.hello); // 打印:函数定义
module.exports.hello(); // 打印:Hello WorldSandbox
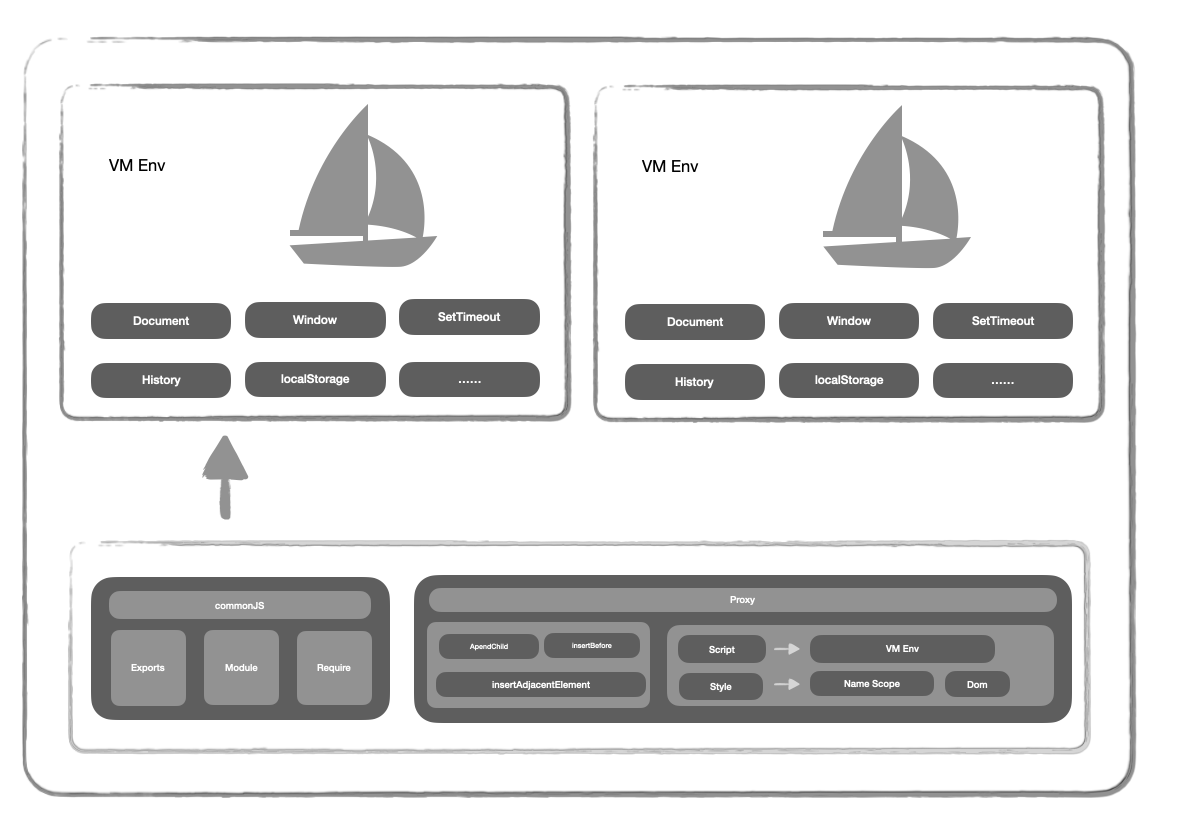
Sandbox 提供子应用运行时环境隔离和公共依赖的复用,可以有效解决同一个文档流内多个子应用样式冲突、全局变量覆盖等问题。
Garfish 支持 快照沙箱 和 VM 沙箱。前者实现简单但无法支持子应用多实例;后者实现复杂但是能力更强大,提供的功能更完整。
这里介绍一下 VM 沙箱:
🔍 展开代码
let code = `(function(exports,require,module,__dirname,__filename){
})`;
vm.runInThisContext(fn).call(module.exports,module.exports,req,module);let code = function(document, window) {
// 实际子应用代码
};
(new Function('document','window', code.toString))(fakeDocument, fakeWindow);// 简易版实现
export class ProxyVMSandbox {
private modifyMap: Record<string | symbol, any>;
private fakeWindow: Window;
constructor() {
this.modifyMap = {};
this.fakeWindow = new Proxy(window, {
get: (target, key) => {
return this.modifyMap[key] || target[key]
},
set: (target, key, value) => {
this.modifyMap[key] = value;
return true;
}
})
}
execScript(code) {
const fn = new Function('window', code);
fn(this.fakeWindow)
}
};重点
- 隔离的沙箱环境:考虑到 Proxy 的兼容性,实际上使用的是 ProxyPolyfill 得到的代理对象作为子应用的执行环境。
- 全局变量的读写保护:重写了 Proxy 里的
get和set函数,这样就可以拦截对window变量的读写。 - 副作用函数的重写:都是依托于沙箱内部的暂存对象,实现了
setTimeout、clearTimeout、setInterval、clearInterval、addEventListener和removeEventListener的劫持和改造。 - 存储前缀添加:通过在
localStorage和sessionStorage存储的 key 前添加沙箱标识的前缀,实现数据隔离。 - Garfish5 实现如上,Garfish3 采用的是快照沙箱,子应用加载的时候
addEventListerner,卸载的时候removeEventListener。但是这样会连带主应用和其他子应用一并取消监听,这也解释了为什么说不支持多实例加载。
❓ 接下来可以看一下,Garfish 在实现 CSS 的隔离方面,是怎么做的。
Garfish3 的核心原理在于——子应用被激活的时候记录当前的 DOM 节点,在移除时比较 head 差异恢复激活前的 DOM 节点环境。这种方式子应用会影响主应用,天然不支持多实例。
Garfish5 的 收集模式 则是将样式文件放在子应用的容器里,在子应用被移除的时候就会自然失效。但是由于没有做 namespace 方案,因此对于多实例的支持仍然欠佳。
实现方式:style 标签放在子应用的容器里,并且新增标签还是通过上面的代理方式做劫持,访问 head 标签的时候重定向到子应用容器的 div 保证位置正确。
为什么不采用 Iframe 来实现微前端?
❌ 大幅增加内存和计算资源,因为 Iframe 需要一个全新且完整的文档环境。
❌ 不属于同一个文档流,事件冒泡与劫持不支持、发生错误主应用不知晓、登录态无法共享、样式不好管理、通信不便等。
📌 提示
至此,借助微前端我们实现了应用的集成。然而新的问题浮出水面,集成后的一整个应用往往会保持 UI 上的一致或者会有很多公共的依赖,那么模块复用和依赖共享问题又怎么解决呢?
💡 应用视角我们可以实现微前端,那么更细粒度,我们是否可以实现微模块甚至是微组件呢?
向下拆解:微组件的逻辑延续
如果说微前端解决的是应用级的解耦,那么微组件解决的就是更细粒度的共享问题。比如一个权限按钮、一个埋点抽屉、一个通用图表,如果每个系统都要自己实现一遍,那维护成本简直灾难。
微组件强调的是功能级别的独立产出与复用。组件被单独构建、部署,然后供多个系统在运行时动态加载。埋点平台出一个通用的“埋点详情抽屉”,别的系统不需要复制粘贴,只要运行时加载这个模块就能用。而且一旦原组件更新,所有系统自动获得新能力,真正实现了组件的“即插即用”。
Vmok
业务能力
模块复用就不多介绍了,简单说一下依赖共享。
虽然 Garfish 也提供了 external 机制来解决主子应用依赖共享问题,但是也会造成二者的耦合,并且一旦升级所有的应用都会受到影响。同时,无法做到同一个依赖使用多个版本,在实际应用中也会有不少限制。
在 Vmok 下,公共依赖可以做到解耦,只要有合适的依赖就会自动复用来减少重复下载。如果没有,就下载使用自身的,也不会强依赖主应用。并且,Vmok 提供了许多公共依赖复用策略给用户配置,框架侧就能做到模块版本的灵活匹配和优雅降级,不必因为一次升级通知所有的应用。
架构方案
Vmok 底层是基于 Module Federation 的,并将这份能力抽象到了 Runtime:
- 可支持动态引入 Vmok 模块,项目可完全运行时接入而无须构建,对搭建场景友好。
- 可以和 Vmok 调试插件、以及运行时下发的模块数据更好的配合,进行整体方案能力的建设。
- 与部署平台更好的结合,结合部署平台下发的数据进行资源预加载,减少运行过程中的瀑布请求,提高运行时性能。
- 可以更加灵活的掌控 shared 复用规则。
- 提供 preload api,用户可以自己控制资源加载,方便进行性能优化。
- 可以做增加链路埋点,否则排查问题将比较困难。
- 抽象出 Runtime 层后,我们设计上采用类似 Garfish 的插件化设计思路,支持在模块加载不同阶段透出不同的 hook , 用户可参与模块加载流程和定制运行时行为(比如模块加载时机打点,探测模块加载性能)。
技术支撑:模块联邦的长处
上面说的微前端、微组件,说得挺好听,但你可能想问:这些到底怎么实现的?Webpack 5 推出的 Module Federation,就是目前解决这类场景的底层利器。
它允许一个项目在运行时动态加载另一个项目导出的模块,而且还能共享依赖,比如 React、Vue 等。这意味着我们不再需要通过 npm 包发布 + 版本控制的方式做模块共享,而是完全可以做到按需拉取、即时使用。
比如埋点团队写了一个模块,只要通过 Module Federation 暴露出来,其他系统配置一下 remote,就能像本地组件一样直接 import 使用。更新也不需要业务方重新发版,只要加载的新模块地址指向新构建版本就可以了。
当然你还得考虑缓存策略、版本回退、加载失败兜底等问题,但相比传统方式,Module Federation 的确让远程模块加载变得更合理、更可靠。
最后的话
技术永远服务于业务,也受限于团队协作方式。MPA、SPA、微前端、微组件、模块联邦这些听起来高大上的词,其实都是架构演化的自然结果。项目小的时候,简单最重要;项目大了,解耦就成了首要任务;协作变多,职责边界就得分清。
我没打算给出某种“最佳方案”,因为真的没有银弹。真正的架构选型,永远来自对团队现状的诚实认知和对业务发展的判断。
你可以从 MPA 起步,走进 SPA,再逐步演进到微前端甚至模块联邦,但别反过来。记住,越复杂的架构,背后需要越成熟的组织配合。